我们假设一个场景,某个客服中心,有几万台电脑,每台电脑上安装了某软件,现在发现这个软件有问题,需要紧急更新,那么如何快速让所有电脑都装上呢?
我们大概有两种方案
- CDN方案
- P2P方案
1. CDN方案
cdn是一种分流,就是将文件推送到多个存储节点,然后客户端从不同的节点下载,避免单一服务器拥塞。
1.1 就近cdn
一般cdn都是就近原则,要么中心化的,提供就近文件下载地址。或者,统一一个地址,然后由dns系统将该域名解析成不同的ip,一实现就近下载。
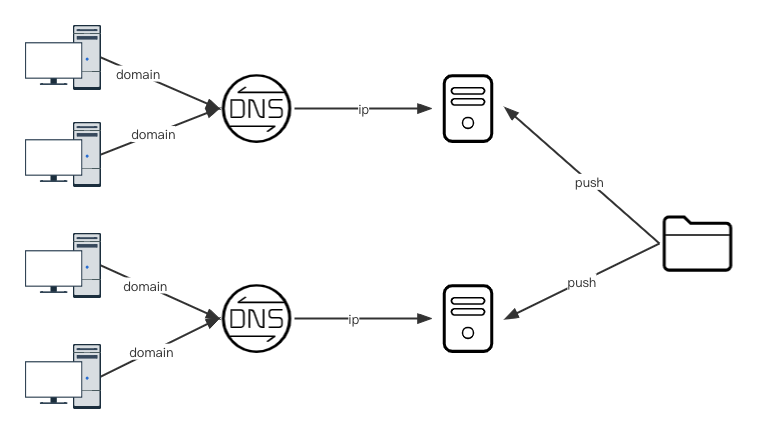
1.2 调度cdn
对于不均等的网络,就近匹配就有问题了,比如网络A有1万台服务器,网络B有1000台服务器,那么势必造成网络流量不均等。为此我们可能还需要实现一个均衡算法,比如VIP(Virtual IP Address)系统。
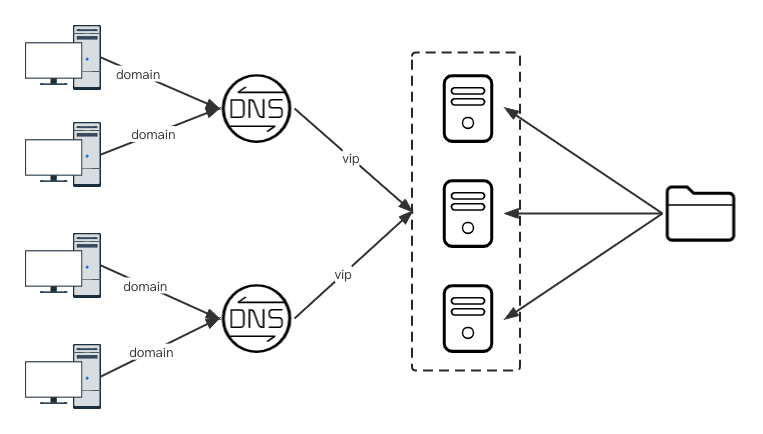
2. P2P
p2p是一种点对点传输,让每个下载节点之间共享传输数据,可以避免服务器的拥堵。类似下图
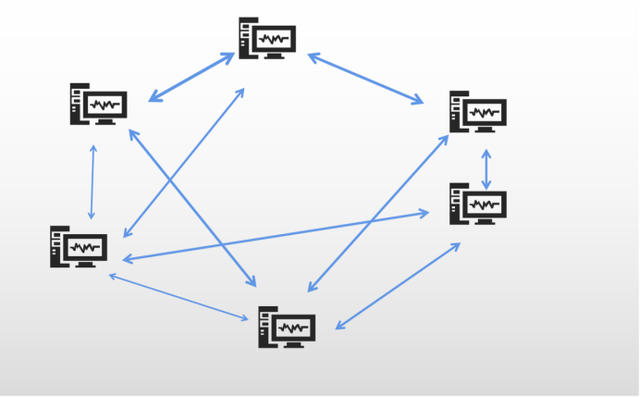
但我设计的p2p不是完全的去中心化的,还是需要服务器进行节点调度分配。大致有以下几点。
2.1分片
分片就是把一个文件切分成很多小块(chunk),每个chunk要至少包含3要素
- seq_id,分片编号
- check_sum 校验码
- data 分片内容
2.1.1 获取文件元信息
元信息至少包含三部分
- 文件名
- 文件校验码
- 分片信息(总分片数,每个分片大小)
2.1.2 获取分片信息
资源池
需要说明的是
服务端也是一个节点,并且有所有的分片内容,因为刚开始下载的时候,只有服务端中心节点有数据。每个客户节点在下载了某分片信息后,它就会把分片编号和自身信息注册到服务端的资源池中,
服务器维护了一个资源池,这个资源池是每个分片对应的可下载的节点信息列表,如下
分配匹配的下载节点
客户端一般会开启多线程并发下载,但下载之前,会批量去中心服务器获取指定的分片信息,服务器会返回以下内容
[
{
"seq_id":1,
"sha":"111111111111",
"endpoint":"192.168.1.2:8080"
}
]
因为第一个节点来请求的时候,此时只有服务器节点才有数据,所以此时会分配服务器节点的地址和端口。为了尽可能的让每个节点的分片均匀分布,每个节点向服务器请求每批的分片的编号不能是从1-N顺序的,而是打乱顺序的。
| 分片编号 | 校验码 | 下载地址 |
|---|---|---|
| 1 | xxxxxxxxx |
[{"seq_id":1,"endpoint":"192.168.1.2:8080"}] |
| 2 | xxxxxxxxx |
[{"seq_id":1,"endpoint":"192.168.1.2:8080"}] |
需要说明的是
服务端也是一个节点,并且有所有的分片内容,因为刚开始下载的时候,只有服务端中心节点有数据。每个客户节点在下载了某分片信息后,它就会把分片编号和自身信息注册到服务端的资源池中,
匹配算法
在局域网内,路由器是通过ip前缀来判断是否是同一个局域网,前缀的长度由子网掩码决定。所以同一个局域网内所有ip一定有相同的前缀。那么反过来说,如果把所有的ip两两对比,每对ip他们的公共前缀越长,那他们处在同一个局域网的概率就越大。我们的匹配算法也是基于此。我们会给他分配一个公共前缀最长的ip。当然,我们也可以考虑其他因素,比如当前节点负载。
2.1.3分片注册
客户端如果下载完某个分片,还需要将自身的ip,端口,分片id,发送给服务器,以便下次有其他客户端请求这个分片的时候,可以就近匹配。
以上是基于点对点方案的一种简单实现,有点类似迅雷,是有中心服务器来保障数据源和节点调度的。P2P在下载时,客户端先解析种子文件得到tracker地址,在连接Tracker服务器,tracker服务器提供其他下载者的地址,下载者之间相互连接交换大家没有的文件块(所谓的下载人数越多,下载网速越快的原理)。很显然,这个中心化的tracker是最大的短板。后来相继诞生了DHT网络技术和磁力链接等P2P技术。两个技术都不需要连接上Tracker服务器,DHT技术将每一个客户的终端作为一个Tracker服务器,每一个客户端仅仅存储一部分路由信息,由全网的所有客户形成一个去中心化的Tracker服务器。磁力链接利用对目标文件进行标记,在全网寻找目标文件,一个文件可以有许多的URL。这样就可以多点下载,同时不用担心某个节点关闭而带来的消极影响。