很多人应该也看过相关的资料,搜索引擎实现搜索的核心就是倒排索引。
见其名知其意,有倒排索引,对应肯定,有正向索引。
正向索引(forward index)就是从文档id到文档内容的映射;反向索引(inverted index)则是term到文档ID的映射。
搜索的时候,先根据条件去倒排索引里搜出对应的文档ID,然后再根据文档ID查出完整的文档内容。
但是在实际的开发中,我需要进行一些取舍,这些取舍直接关系到后续的扩展性和运行效率。
存不存完整的文档内容。
拿我们常用的es来说,它其实不仅是一个搜索工具,本身还是个分布式文档数据库。可以用oid来直接读取文档内容。但实际是我们并不太需要它的文档存储功能。因为搜索引擎本身只是个工具,它的数据来源于其他存储工具,所以只需要搜出一个id即可,具体的文档内容我们可以从原始的存储工具里去获取,还可以加上缓存。所以开始我只是想做一个简单的搜索工具,只需要搜出id可以,然后根据id由运用层去缓存,去数据库,去文件获取完整的数据。
需不需要添加快照(版本号)。
在我们更新一个文档的时候,有2种方式:
- 直接根据文档id跟新,以文档id当做文档物理存储的唯一标识。
- 把文档id当做一种特殊的字段,修改的时候新插入一个文档,同时利用一个版本id来当做实际物理存储标识。
最终,我选择了文档完整存储,通过版本号来当做物理存储标识。关于完整文档存储完全基于个人喜好来判断的,而通过版本号来标识文档的物理存储则是基于性能考量。我们知道,文档的修改实际是分为两步的,1是读取,2是写入。但是因为这两步都有随机性,所以会造成性能的损失。如果通过版本号这个概念,则一直是“追加”写入,性能会大幅提升。
因为底层存储是KV格式,所以实际在存储一个文档的时候,又存在两种方式:
- 文档整体存储,类似于一个json。
- 分字段存储,每个字段有独立的版本号。
显然第二种最灵活,扩展性最好,同时修改的时候,可以进行部分字段修改。第一种方案要想修改,需要先查出完整的文档,然后再修改。但是因为我们原始的数据在数据库,所以我们是可以从缓存或数据库取出需要索引的完整的数据的,并不需要去索引引擎你去查全部的数据,所以我最终选择了第一种方案。它查询的时候,要根据文档id和字段编号(名称)查出多组值,然后取版本号最大的那组kv。
确定了以上几个方案后,最终就是实现了。
我们底层采用RocksDB来存储实际数据。采用前缀搜索来查找数据。
其中倒排索引和正排索引的数据组成如下图:
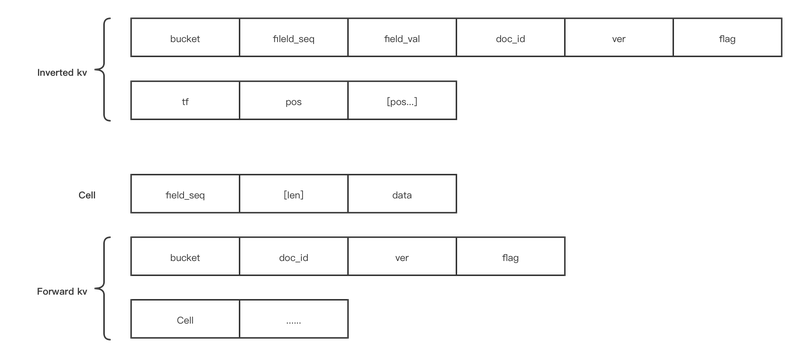
当我们查询的时候,根据当前的库和字段值,组装出前缀${bucket}${field_seq}${field_val},可以通过迭代器查出一组kv,然后我们在迭代的过程中,通过删除标记flag过滤点已经删除的kv,同时相同的doc_id里,取版本号ver最高的那一组kv。
此处需要注意的是,针对数值型索引,我们有两点要考虑:
- 范围查询的时候,
field_val取的是公共前缀,比如[123,134],field的值应该取1。 - 对于有符号的数值,负数因为高位为1,所以在byte排序的时候,负数在正数后面,这是不正确的,所以我们需要把正数的最高符号位变成1,把负数的最高符号位变成0。
val = val ^ 0x80000000;
具体的数值和字符串怎么拼接,请看上节内容Stream的使用。
在大多数情况下,我们只要查出doc_id就可以了,剩下的文档内容是由缓存或数据库去查询解决,并不需要搜索引擎来获取。如果要获取文档内容,则需要用正排索引了。
基本的数据结构如下:
struct Column {
std::string name;
uint8_t type;
uint8_t seq;// the sequence in bucket
};
struct Field {
Column* col;
uchar_t * raw;
size_t len;
};
struct Bucket {
std::string name;
std::vector<Column*> cols;
};
typedef std::vector<Field*> Document;