Buffer,Stream,Encoding这三者算是底层基础服务。尤其是buffer,几乎每个模块都需要用到。
其中encoding是用来将数据系列化为可存储字符串,stream是数据类型转换的,buffer是底层数据存储。
下面具体谈谈各模块的设计。
Buffer
buffer 指一般的应用层缓冲区、缓冲技术。主要用作读写速度不匹配或者chunk读写。类型分为单端buffer或双端buffer。
因为考虑到多场景使用,所以我直接将其设计成了双端buffer。buffer的底层数据是一块连续的内存空间。基本结构如下
struct Buffer {
uchar_t *_m_buffer;
size_t _pos;
size_t _size;
size_t _capacity;
}内存布局如下图:
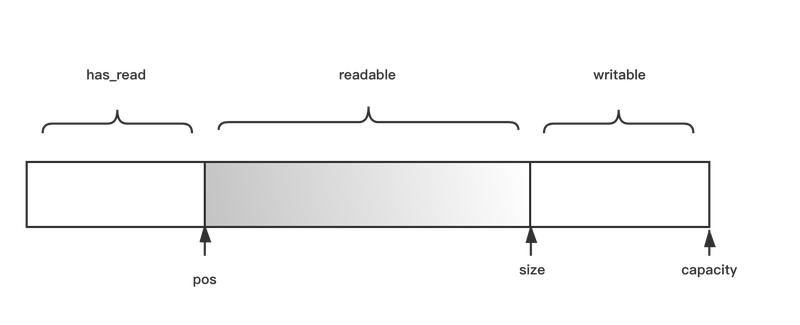
其中capacity表示物理存储大小,size是实际的使用大小,pos是已读的位置。
当capacity容量不够的时候,_m_buffer是可以扩容的,我们用的realloc函数来进行扩容。所以这里需要特别注意_m_buffer的指针地址不一定固定不变。
另外,为了提高内存的使用效率,我使用了jemalloc来进行内存管理。我们通过宏来替换原生的内存申请释放函数
#include <jemalloc/jemalloc.h>
#define malloc(size) je_malloc(size)
#define calloc(count, size) je_calloc(count,size)
#define realloc(ptr, size) je_realloc(ptr,size)
#define free(ptr) je_free(ptr)
#define mallocx(size,flags) je_mallocx(size,flags)
#define dallocx(ptr,flags) je_dallocx(ptr,flags)为了减少分配次数,我们会按一定的策略冗余申请内存,代码大致如下:
void Extend(uint32_t len) {
size_t alloc_size = 4; //default 4 byte;
while (alloc_size < 1024 && alloc_size < _capacity + len) {
alloc_size *= 2;
}
while (alloc_size < _capacity + len) {
alloc_size += (alloc_size >> 2); // increase by 1/4 allocate size
}
if (_m_buffer == nullptr) {
_m_buffer = (uchar_t *) malloc(alloc_size);
} else {
_m_buffer = (uchar_t *) realloc(_m_buffer, alloc_size);
}
_capacity = alloc_size;
}buffer的shrink
一般的buffer都是临时使用,使用频率也不高,所以上面的设计没有问题。 但是如果频繁的写入读取,就不难发现,底层存储会膨胀的非常厉害,前面那一段已读的空间非常大,但它他们又没有任何使用价值,所以复用这一段已读空间非常重要,要想复用,无非就两个途径:
- 将底层空间弄成环形,类似于环形队列
- 数据挪动 第一种类似于我们在学数据结构的时候的环形队列,它的优点是内存利用率高,但缺点则是适用场景苛刻,就是读取速度跟写入速度差不多的时候才有效果。 第二种则相反,只有符合条件才会触发,其他场景无需特殊处理。 综合考量,我选择了第一种
void BytesBuffer::Shrink() {
if (_pos >= (_size - _pos)) {
memcpy(_m_buffer, _m_buffer + _pos, _size - _pos);
_pos = 0;
_size -= _pos;
}
}Stream
stream是C++标准库中的<sstream>的简单功能实现,但只用于数值和string到字节数组的转换。底层用的是上文中的buffer。
标准的用法为:
BytesStream bs(8);
uint16_t u16;
bs << uint16_t(100);
bs >> u16;
std::string s1("abcsdddddd222222222222222222");
bs << s1;
std::string s2;
bs >> s2;通过<<和>>运算符重载来实现void WriteByte(uchar_t *buf, size_t len)和void ReadByte(uchar_t *&buf, size_t len)
但核心的其实是数据转换,代码大概如下
template<typename T>
void ConvertDigitToBytes(uchar_t *&buf, T v) {
const size_t size = sizeof(v);
buf = (uchar_t *) malloc(size);
for (size_t i = 0; i < size; i++) {
if (i == 0) {
*(buf + i) = static_cast<uchar_t>(v >> (size - i - 1) * 8);
} else {
*(buf + i) = static_cast<uchar_t>((v >> (size - i - 1) * 8) & 0xFF);
}
}
}
template<typename T>
T ConvertBytesToDigit(const uchar_t *buf) {
T data = static_cast<T>(0);
const size_t size = sizeof(data);
for (size_t i = 0; i < size; i++) {
data |= ((T) *(buf + i) << (size - i - 1) * 8);
}
return data;
}可以看到,对于数值型变量,其占用内存是固定的,所以很容易算出其占用的字节数。
但是对于字符串,它是变长的,所以在读取的时候,你无法直接算出读取的字节数,所以对于字符串,需要特殊处理。需要在数据区域的头部,存入长度。类似如下结构:

在数据的头部,先存字节数,后面才是数据内容。在读取的时候,先读头部区域获取字节长度,然后读取数据内容。那么,这时问题又来了,这个size应该用什么格式存呢?用8字节的unsigned long long int 肯定是够的,4字节的unsigned long int在绝大多数情况下也是够的。其实平常2字节unsigned short int就行了。如果为了保险用8字节或4字节来存储长度,那肯定会大大浪费存储空间。
那么有没有一种更省的方法呢?
答案是有。其实我们最容易想到的就是utf8编码。
UTF-8是这样做的:
单字节的字符,字节的第一位设为0,对于英语文本,UTF-8码只占用一个字节,和ASCII码完全相同;
n个字节的字符(n>1),第一个字节的前n位设为1,第n+1位设为0,后面字节的前两位都设为10,这n个字节的其余空位填充该字符unicode码,高位用0补足。
这样就形成了如下的UTF-8标记位
0xxxxxxx
110xxxxx 10xxxxxx
1110xxxx 10xxxxxx 10xxxxxx
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
... ...
观察可得,utf8可以做到动态存储。大部分的数字,用1-2个字节即可存储,更长的也能支持。但可以看到,除开第一个字节的头bit,后面的10是没有必要的,utf8这么多,是为了校验和纠错。避免串位。但是我们并不需要,所以我们可以进一步精简,如下所示:
0xxxxxxx
110xxxxx xxxxxxxx
1110xxxx xxxxxxxx xxxxxxxx
11110xxx xxxxxxxx xxxxxxxx xxxxxxxx
111110xx xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx
1111110x xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx
... ...这样有效的存储bit会稍多。写入或读取过程如下
void BytesStream::_WriteStrLen(uint32_t len) {
if (len <= 0x7F) {
WRITE((uint8_t) len);
} else if (len <= 0x3FFF) {
uint16_t i = (uint16_t) len | 0x8000; // set highest two bit to 10
WRITE(i);
} else {
uint32_t i = len | 0xC0000000; // set highest two bit to 11
WRITE(i);
}
}
uint32_t BytesStream::_ParseStrLen() {
uint32_t len = 0;
uint8_t byte1;
READ(byte1);
if (!(byte1 & 0x80)) {
len = byte1;
} else if (!(byte1 & 0x40)) {
uint8_t byte2;
READ(byte2);
byte1 &= 0x3F;
len = (byte1 << 8) | byte2;
} else {
uint8_t byte2, byte3, byte4;
READ(byte2);
READ(byte3);
READ(byte4);
byte1 &= 0x3F;
len = (byte1 << 24) | (byte2 << 16) | (byte3 << 8) | byte4;
}
return len;
}写入过程就不说了,读取过程大约是先读取一个字节,根据头部bit算出动态字节数,然后通过位移算出最终的数值。
Encoding
其实说完前面,encoding就不用太多解释了,其实就是重载出不同的构造函数,将参数写入BytesStream,然后一次性取出,得到的字符串就是最终的结果。