在我们日常开发过程中,缓存设计和运用是必不可少的一个环节。
我们常见的缓存策略包括:
- Cache Expiry
- Cache-Aside
- Read-Through
- Write-Through
- Write-Behind
- Double Delete
上述内容的具体含义,可以网上搜索一下,或者参考这篇文章 Cache Policies.
缓存的使用可以大大降低系统的负载,提高系统的吞吐量。上述六种,尤其是第一种基本可以解决我们绝大部分的业务场景。然而,每当系统数据更新时,保持缓存和数据源(如 MySQL 数据库)同步至关重要,当然,这也取决于系统本身的要求,看系统是否允许一定的数据延迟。
我们设想一下以下场景
假设有两个请求,A请求是读,B请求是更新,可能会出现的问题:
1.缓存刚好失效或者本来就没有缓存
2.线程A查数据库,得到旧值
3.线程B更新或删除数据库数据
4.线程B删除或更新缓存
5.线程A更新缓存
这种场景下,Double Delete虽然基本能满足要求,但是时间间隔并不好确定,在这个时间间隔内,问题依然存在。
这个问题也并不是cache独有,很多场景都存在,尤其是我们用的最多的mysql。在MySQL InnoDB中,通过引入MVCC实现读-写冲突不加锁,而这个读指的就是快照读, 而非当前读,当前读实际上是一种加锁的操作,是悲观锁的实现
所以,我们不妨借鉴一下类似的思路来解决我们的问题。
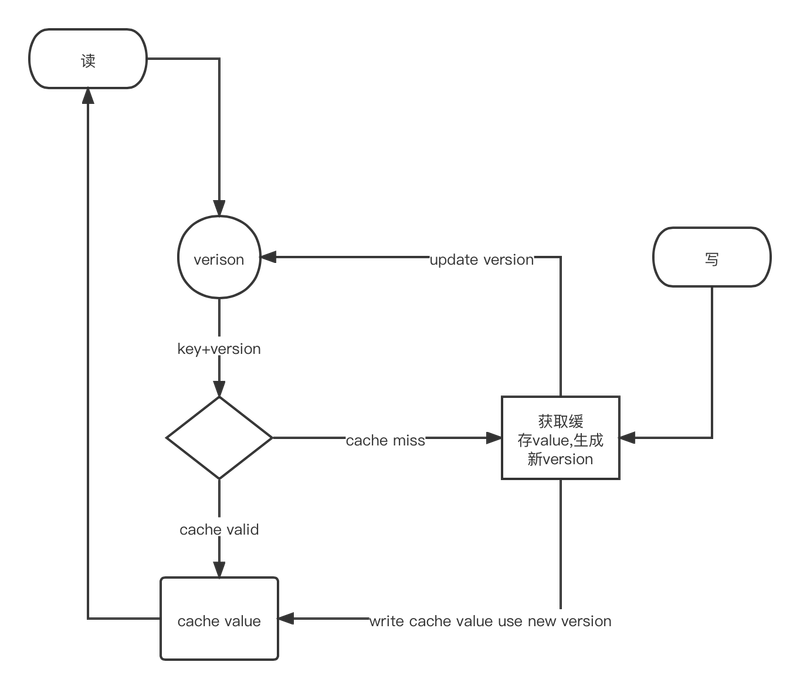
我们为每个缓存实体引入一个版本号,这个版本号的粒度取决你的业务需求,比如一篇文章,一个人,一笔交易,一个商品等。
- 在读取缓存的时候,我们先去获取这个版本号,然后以
key+version当做key去获取缓存。如果miss,反种缓存也是以key+version当做key去种。 - 在写入缓存的时候,先生成一个新的版本号,比如
version+=1,然后以新的key+version种下缓存。刷新版本号。
大致过程如下图
注意的是
- version只要不重复即可,并不必须是数字。
- version最好在一切准备就绪,即将写入缓存的时候生成,保证写入的顺序性。
- version必须是原子性的,否则version的
读-写会成为另一个冲突点。当然如果并发不是特别高,version可以取毫秒时间戳。
其实,我当初设计这个时候,还有另外一个目的,就是大批量清理缓存.当时是一个日程系统,一个日程最多有6万人,每天重复的话,一周都有42万个事件。每个事件都有独立的接受状态,评论等。当这个日程修改或取消的时候,我需要刷几十万个缓存,工作量太大。如果日程有个版本号,那问题就好办了,我只需要刷新这个版本号就行,旧的缓存自然就读不到了,让它自然过期即可。