公司之前用的是钉钉作为办公软件,但是因为某些原因,公司高层决定开发自己的办公协作产品。该项目于2019年5月立项,本人是当年8月底加入,加入后本人就负责整个日程模块的设计工作。其实在我之前日程已经有过一版,但是因为无法实现全部功能,导致无法推进下去了。因为本身还没开发很多东西,项目也没上线,所以我彻底推翻了以前的设计,重新设计了整个模块。
架构
我们整个的软件就是对标的钉钉和飞书,日程也是如此。所以我们的第一个目标就是实现飞书和钉钉的所有功能。做到人无我有,人有我优。
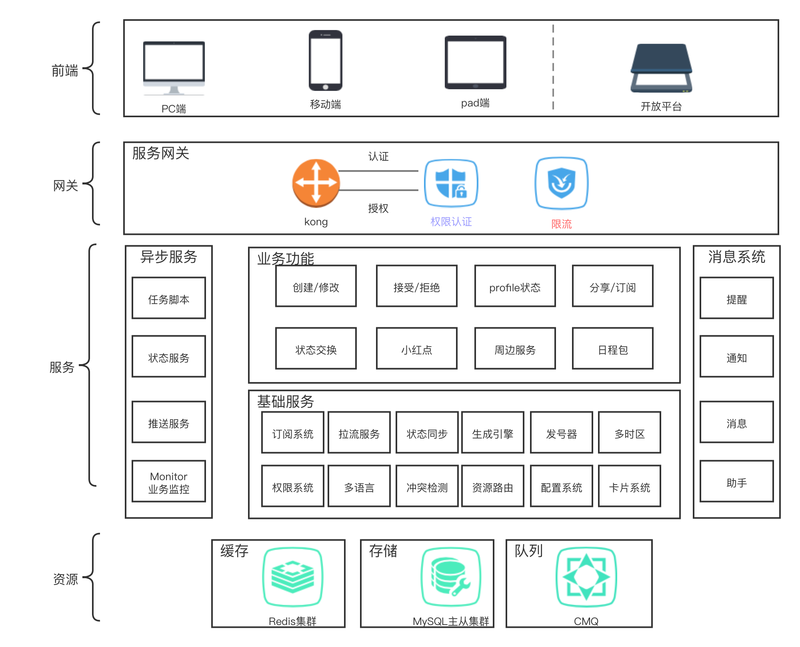
从上图看,整个系统可以分为日程和周边服务。毫无疑问,日程是核心。
沟通+共享文档+日程协同,是办公协作的三大核心场景。日程是连接办公活动的枢纽。日后几乎所有与时间有关的业务都会接入日程系统。所以我在日程里抽象出了一层基础服务层。这一层的作用主要是将底层数据和业务系统隔离。我们知道,重构是稳定性的大敌,但是在我们的日程开发中,尤其是一个快速上线的产品,随着业务的变动,底层数据结构是会频繁变动的,底层一动,业务系统会跟着动,稳定就无从谈起了。而抽出的基础服务层,接管了数据库,缓存,队列等底层存储的读取和修改,还提供了一些基础的公共服务,隔离了数据存储和业务实现,它可以是项目里的一个代码模块,也可以是一个微服务,还可以是一个第三方提供的api接口。
技术难点
虽然产品是对标的钉钉和飞书,但是在网上几乎找不到任何有价值的文章,搜索引擎搜出的都是毕设层次的内容。所以一切只能自起炉灶,从头设计。
- 模型的选择,读扩散和写扩散的权衡
- 缓存的一致性和命中率的矛盾
- 日程变动造成的处理数据膨胀
- 日程分裂问题
- 多语言,多时区,多端,多版本支持
- 与数据库无关的事务系统
- "小红点"对性能的影响
- 缓存的复用率
写扩散
我们将一次提交,称为一个Task,它最要的四要素为uids,start_time,until_time,rule,其中rule是重复规则。until_time是重复结束条件,可以是时间戳,也可以是重复总次数。
我们在客户端的日历里看到的是日程事件(Event),它们是根据uid和rule展开后生成的。比如uid有20个,按天重复,重复10天,那么最终的Event数量为20 * 10 = 200条。如果人数较多或者重复次数太多,那么事件数量会非常大。会造成数据库写入压力。那么在创建日程的时候不展开,在读取的时候展开行不行呢?这里会有2个问题:
- 用户进入日程列表的时候,查询条件是uid和时间,但是未展开之前,时间是不确定的,比如每10天重复一次,重复100次,每次上午9点到10点触发。如果没有事先展开,是无法确定时间段内是否命中该日程的,也无法查询。
- 未展开前,如果有用户对该时间进行接受,拒绝,删除等操作,只能先记录,然后展开的时候根据这些操作
复现,大大增加了事先难度。
所以,我最终选择了写扩散,在创建的时候,就展开。需要说明的是,对于按月,按年重复的日程,我会展开10年,按天重复的日程,我会展开2年。提交的时候,只创建当月的日程,剩下的由异步脚本创建完成。另外,这个决策还有个关键点是,日程是典型的"一写多读",从直觉上说,写扩散对风险的把控度更高。读扩散模式下,一旦出现问题,影响大得多。
在展开的时候,我们又抽象了一个东西Agenda,它是与人无关的,只与重复规则有关。比如一个20人的日程,按天重复,重复10次,那么就有10个Agenda,每个agenda下对应了20个人。也就是说,Agenda数量乘以总人数,得到最终的事件数。之所以抽象出agenda,是为了“开始前提醒”,因为开始前提醒是先通过延迟队列查出agenda_id,然后查出agenda对应的每个人的事件,最后根据每个人的事件状态决定是否推送。
缓存设计与“小红点”
对于一个日常办公的产品,用户操作流畅度肯定是比较核心的指标。尤其是月视图和“小红点”,因为一次需要拉取一个月的日程事件并计算出事件总数,所以对性能提出了很大挑战。同时,日程又是个数据强一致性的产品,并不能像普通的文章类产品设置一个过期时间等待正常淘汰。
要想提高缓存的命中率,我们需要提前主动刷入缓存。但是对于数据频繁变动的业务来说,当数据发生变动,又需要修改或删除旧的缓存数据,你往往并不知道需要刷新的缓存key有哪些。比如你修改了一个日程的重复规则,你无法得到参与者各自的缓存key是什么,你需要将所有的人的事件id查出来,拼凑出对应key,然后进行更新。这个过程显然太重了,而且大量的缓存无法一次刷新,多次刷新会造成刷新过程中短暂的数据不一致。
为了决绝缓存更新问题,我们设计了一个"数据和结构分离"的模型,数据指的是具体一条数据,比如日程事件

一个事件就是一个对象,通过prefix+${sid}进行缓存。
而我们在实际的逻辑处理的时候,其实并不需要完整的事件内容,需要的是各种id的映射。不如我们在拉取日程的时候,实际是根据uid和时间拉取,如下图:
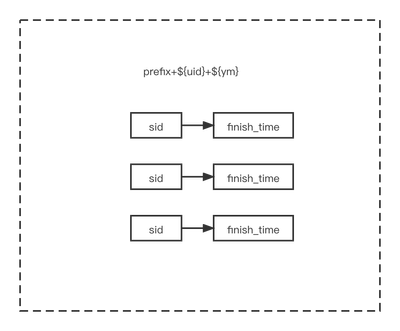
我们可以用一个zset或list来存储,因为sid本身是用发号器生成的,里面包含了begin_time,所以,我们先定位到月feed缓存,然后取出一批数据,解析出begin_time,然后再过滤掉。
当我们修改日程的时候,实际是修改了task信息,这个时候,我们并不管以前的event旧数据,而是重新生成了一批event,并重新种下缓存。那么这个时候,其实新旧数据是共存的。但是我们可以通过event数据里的eid取出task信息,然后根据task的ctime跟event的ctime,对比,如果不相等,自然就是旧数据,过滤掉即可。这就是一种乐观锁。
但是,新的问题又出现了,我们无限修改,那么数据会不会无限膨胀呢?这个问题是存在的,所以我们在取出过滤完了数据后,需要计算一下有效数据和拉取的总数据的占比,如果低于阈值80%,会往队列写入一个消息,又异步脚本来清理无用的数据。
“小红点”就是在有日程的日期下面显示一个小红点,默认显示一个月的日期,实际跟拉月列表是一样的,不过一天只要判断有一个以后,后面就不用判断了。
日程分裂和数据膨胀
所谓日程分裂,指的是一个重复日程,从中间某一天修改,如果选择修改本次,那么该日程就会独立出来。如果是修改本次及以后,那么整个日程就会截断,本次以前的跟本次及以后的变成两条日程。
比如一个100人的日程,重复200次。如果我在重复第100次的地方修改标题,并且修改本次及以后。那么我需要修改后100*100条Event数据。这个处理难度就太高了。尤其是我们修改了数据后,还得刷新缓存。
为此,我们设计一种“只增不改不删”的模式。当我们修改日程的时候,我们并不修改或删除旧的数据,只是标记下删除点,然后我们以删除点为起始时间,生成一批新的数据。至于旧的数据,我们在拉取数据的时候给过滤掉,并通过异步脚本来保证80%的正常率。
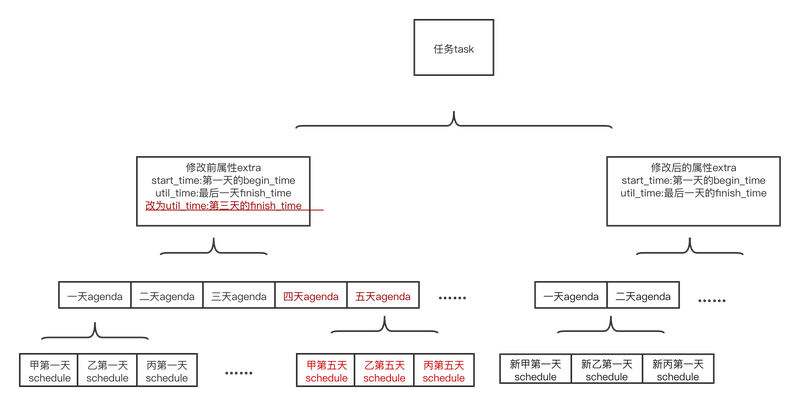
如上图所示,假设我们从第四天修改日程,那么,我们只需要将原来的日程的util_time改成第三天的finish_time即可,然后我们以第四天的begin_time为start_time,生成一批新的数据写入数据库,并重新种缓存。当前端在拉取数据的时候,或判断Event的begin_time和对应task的utile_time,如果util_time小于改日程的begin_time,则舍弃该数据。
事务系统
事务主要就是ACID四大特性了,如果逻辑简单且数据量小,数据库本身就提供这些功能。但是数据量较多,或者跨库就比较麻烦。我们在设计日程的时候,本来mysql就是权宜之计,未来可能会用MongoDB或hbase或cassandra。因为我们的事务系统本身就不与数据库绑定,我们设计了一套与数据库无关的事务系统。
针对我们具体的场景,如果操作失败,我们并不需要“回滚”,而是让数据"废弃",而“废弃”的意思就是让数据不生效,我们只需要给这批操作一个状态值即可,如果状态值不对,我们在前端输出的时候,过滤掉即可。在开发中,我们碰到过两种情况:
明确的主副关系。比如日程和日程事件,主线就是日程,只有所有的操作都成功了,改日程的状态才是"成功",否则就是“待完成”。在我们输出日程的时候,凡是日程状态不是“成功”的都过滤舍弃掉。
对于没有明确的主副关系的数据写入。则需要独立设置一个状态表,通过状态状态表的主键id来关联,凡是状态不对的数据,通通过滤掉。
缓存的复用率
缓存的命中率决定了程序的响应时间。但是过多的缓存会给数据的一致性造成压力。比如我们拉取自己的已经拒绝的日程列表,已经接受的日程列表,未过期的日程列表...等等,如果我们各维持一套缓存,那么在数据更改的时候,需要刷新多条缓存,增加了业务负担。
所以,在提高缓存的命中率的同时,更应该提高缓存的复用率。
我们给每个人只维持一条数据缓存,称之为“管道”,用户在拉数据的时候,会拉出全部缓存数据,然后过滤掉不需要的数据。为了提高效率,我们可以用redis的zset来存储,其中score存的是日程的结束时间戳,不过为了区分,我们给不同的状态加上了不同的基数,比如接收的日程,我们在时间戳的基础上加上1000000000,拒绝的加上2000000000。这样我们根据score的区间就能拉出需要的日程事件。