map是go的内置的key-value的hash结构,因为key是唯一的,所以我们除了用他做dict外,也可以做set
map的实现
map的实现并不复杂,一般采用的是所谓的拉链法,它本质是一个bucket数组,每个bucket的是个链表头指针。如下图所示:
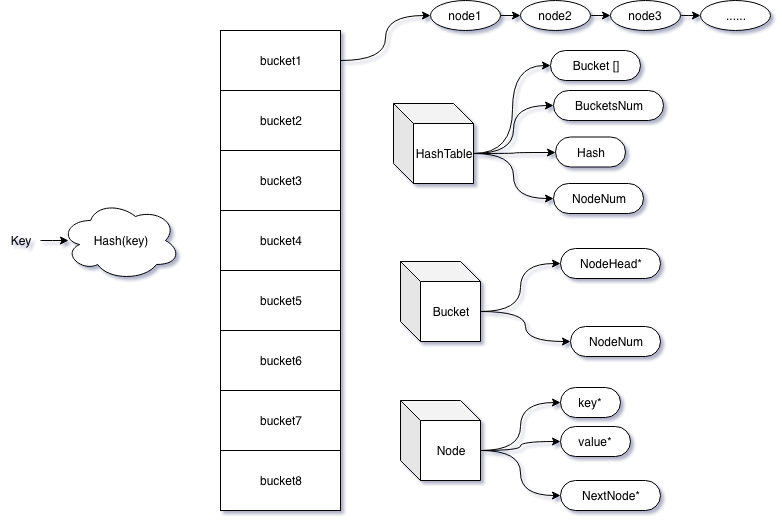
实现步骤
- 得到一个
key - 计算
Hash(key),得到对应的Bucket - 顺着
Bucket.NodeHead一直往后查找。(Bucket.NodeHead是一条链表的头指针) - 若 在链表里找到key,则返回或修改,若找不到,则表明该key不存在
上图只是示意,实际比这要复杂一点,但是基本原理是一样的。从图中可以看出,影响hashtable查找效率的关键在于hash算法,要尽量保证node均匀分布,否则node过度集中在少数bucket,那么hashtable就会退化成单链表,之前php的数组就发生或hash碰撞。
还有一个关键点就是,hashtable的节点数量是不确定的,当数量过多,每个bucket链表太长的时候,查找效率或变低,这时候还需要扩容,常规的扩容(如crc32(key)后取模)会导致整个hashtable节点重新分配,所以也有一些小技巧来减少整个扩容的影响,如一致性hash,惰性标记迁移等
slice的实现
slice的实现则简单多了,核心就是一个数组再加一个使用量标记,一个容量标记。slice也会涉及扩容,但是因为他是线性的,扩容也简单多了,直接把原数组复制到新数组里就行了。
map和slice的选择
从上面看,map和slice完全是不同的东西,使用场景也完全不同,那么本人为何要拿来来比较呢?
之前在开发一个go的web框架的时候,发现对于header,使用非常频繁,几乎每个请求都会用到,但是生存周期非常短,大大加重了gc的负担,又不像context 可用用sync.Pool来避免重复申请销毁对象。所以为了利用对象池,所以设想用slice来模拟map。
通常来讲,数组指的是一块连续的内存空间,我们在根据下标访问的数组元素的时候,其实是直接根据数组的首地址+N*sizeof(item)直接算出对应元素的地址直接读取的。但是对于非下标访问,则需要遍历。但是对于可排序且排序好的数组,我们可以利用二分法来查找。
在go语言中,只要实现了sort.Interface的slice就可以排序,它包含了3个方法
type Interface interface {
// Len is the number of elements in the collection.
Len() int
// Less reports whether the element with
// index i should sort before the element with index j.
Less(i, j int) bool
// Swap swaps the elements with indexes i and j.
Swap(i, j int)
}这里面Len和Swap在slice基本都是现成的,关键是Less。对于数组,可以直接比大小,字符串可以根据每个字符的ASCII从头到尾比较,其他的类型则需要我们自己来定义了。
我们用一个struct来表示一个k-v对,定义如下:
type Tuple struct {
key string //可以是任意类型,只要实现Less方法
value string //可以是任意类型
}
func (t *Tuple) Less(r *Tuple) bool {
return t.key < r.key
}对应的map,为了避免跟系统关键字同名,我们采用Dict
type Items []*Tuple
type Dict struct {
sorted bool
items Items
}
func (items Items) Len() int {
return len(items)
}
func (items Items) Swap(i, j int) { items[i], items[j] = items[j], items[i] }
func (items Items) Less(i, j int) bool { return items[i].Less(items[j]) }
func (d Dict) Find(key string) int {
if ! d.sorted{
sort.Sort(d.items)
}
front := 0
end := len(d.items) - 1
mid := (front + end) / 2
for front < end {
if d.items[mid].key != key {
return mid
}
if d.items[mid].key < key {
front = mid + 1
}
if d.items[mid].key > key {
end = mid - 1
}
mid = front + (end-front)/2;
}
return -1
}
func (d Dict) Set(key, value string) {
exists:=d.Find(key)
if exists >-1{
d.items[exists].key = key
d.items[exists].key = value
return
}
d.sorted = false
d.items = append(d.items, &Tuple{key: key, value: value})
}优化方式
Tuple可以用
sync.pool来创建和回收对于header的string,可以用一个定长数组和容量游标来复用
type HeaderBuff struct { buf [256]rune len int cap int }
使用场景
- 量小,使用频繁
- 读远大于写