第一面
本来我是想找个php或go的位置的,结果猎头把我推到蚂蚁金服的搜索推荐部门。
第一面在环球金融中心九楼现场面试的,问的问题不算特别难,大部分记不清了,只记住一些印象比较深的问题。
请说说c++是怎么实现多态的
是利用虚函数表来实现的,每个虚函数类的内存开头都有一个虚函数表,里面存储了虚函数指针地址,当用父类指针调用派生类函数的时候,会去虚函数表里寻找函数指针然后调用
gdb调试你知道的参数有哪些,代表啥意思
我表示gdb用的不多,只知道-bt是打印调用栈,平时直接用IDE调试。
跳跃表结构
我理解跳跃表就是索引的索引,一个单链表查找数据需遍历,遍历的时间复杂度是O(N),为了减少时间复杂度,所以在这个单链表上简历索引,逐步缩小查找范围,但是当数据太多的时候,单层索引可能不够用,所以会弄很多层索引,也就是索引的索引。这种结构理解起来不复杂,但是写起来还是挺麻烦的。
new和malloc的区别
malloc就是单纯的分配内存,但是new还会调用构造函数。我曾经做过内存池,就是重载new和delete,分配内存的时候,从一个deque里面取,delete的时候,把内存放回deque,这样可以避免重复的申请内存。
简述全文索引工作过程
全文检索分3部分吧,1是文章抓取,2分词,归一化根据term建立倒排索引。3是搜索的时候对搜索语句进行分词,归一化处理,然后在每个term里抓出文章id,计算相关度并排序输出。
你觉得全文检索的核心是什么
当然是分词了。分词的难点在NLP。低层次的分词就是一个字典查找。但是复杂的,还有结合搜索上下文,用户信息,当前的时间,地点,以及社会热点等综合理解。现在机器学习比较火,我理解的机器学习就是一个黑盒,根据训练,找出各个维度数值的系数,然后打分。
说说你对分词的理解
分词就是把一个句子拆成词,我个人认为主要分两类,1是字典比对,就是前后两个游标,他们框出的字组成的词拿去字典比对,是词的话就摘出来,当然有按拆分最细分的,有按当个词最长原则分的。2是统计分词,就是N-Gram分词,按固定的长度把句子拆成词,然后统计每个词出现的频率,如果出现频率高可能他是个独立的词,否则就不是。这两种方法各有利弊,词典法主要是简单,速度快。缺点是无法识别词典以外的词。统计法就相反了。
分布式原理
分布式主要有两点
分布存储,就是数据根据一定的映射规则分散到不同的机器或虚拟节点
主从存储,每个机器或节点会有一个master,一个或多个slaver.在设计数据的增改删的时候,是master节点来操作的。当涉及读的时候,只从slaver读或master和slaver随机。
分布存储是因为数据规模比较打,单机或单节点无法承载所有的数据。所以需要把数据分散。分散规则有多种,比如es是取模,比如redis是crc16,还有memcache集群的一致性hash。
主从主要是保证可靠性的,因为机器或节点可能挂掉,挂掉要保证整个系统可用,而且数据不丢。所以需要有备份。但是多备份涉及到数据一致性问题,所以一般都是1主多从。当主节点挂了,会选举一个新的主节点。为了实现节点的监控,所以可能还需要一个监控系统,比如zookeeper或sentinel。选举协议paxos或raft.在选举的时候,为了防止集群分裂,所以只有半数以上的集群才会选举。
怎么实现geo搜索,比如你周围的商家
把地图化成小格子,每个格子建立倒排索引。在查找的时候,根据当前位置和距离半径算出符合条件的格子,然后遍历每个格子进行筛选。我在微博的时候,我们存储用户位置的时候,用了
geohash来筛选附近的用户。
说说你对搜索引擎的认识
搜索引擎我觉得应该分两步吧,一个是索引,一个搜索。当数据录取的时候,对他进行过滤,同义词转换,归一化处理,进行分词,然后根据分词进行倒排索引。查询的时候,对查询语句也要进行上述操作,然后去对应的倒排索引找出文档id,然后合并啊,排序什么的。现代的搜索引擎应该不算是单纯的全文检索工具了,还有一些个性化的内容,比如根据你的年龄,地域,上下文进行相关的推荐。所以搜索引擎=全文检索+推荐
说说根据倒排索引多个term的AND和OR的查找过程
我当时在纸上花了一个倒排索引的图,然后对着图讲解,图大概如下
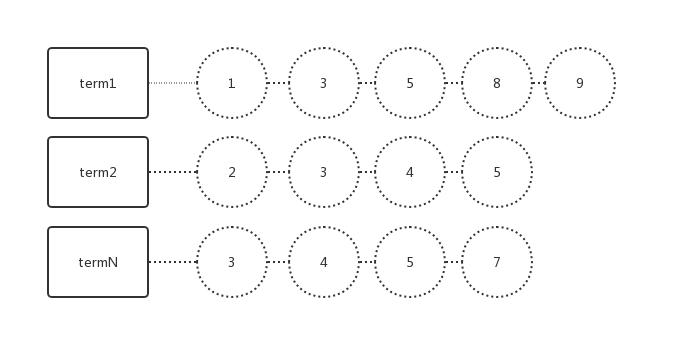
首先讲指针移到第一位,获得1-2-3
如果不等,找出最大的那个;比如图中1-2-3,的termN的3,剩下的节点一直往下移,直到值大于等于当前最大值,这时都 停到3,把3摘出来,
所有指针下移一步,如图中5-4-4,这时最大的是5,那么term2移到5停止,termN移到5停止,5摘出来,所有节点下移一位
这时term2没有了,寻找停止。
上述是and,or类似,只是判断条件不在于相同,而是满足一个即可
你之前做过哪些与搜索相关的东西
我表示,我在微博头条做过app的搜索功能,是用es用的,当用户进行搜索的时候,先根据搜索词,再加上文章发布时间,文章的level,虑重标记等搜出100条数据,然后根据这100个oid去redis里获取他们的转评赞。最后根据es的相关度score,文章热度,转评赞利用一个公式算分排序,缓存并输出。
es的排序策略是怎样的,有哪些问题,怎么改进
es的排序是df-idf以及后来的bm25。就是说一个词在这个文档出现的次数很多,但是在所有的文档出现次数很少,那么就说明这个词与这个文档最相关。但是问题就是关键词堆砌,就是以前seo经常搞的,一个词反复出现。解决方式就是,在计算df的时候,还需要引入文长。另外这种算法对短文比较有利。bm25有一些改进,但是也没有解决。应该加入其它的一些因素比如作者等级,用户转评赞平分等综合排序。
现场写代码,找出转折数字
听说现场写代码,当初还是比较紧张的,但是问题一出,心里就窃喜了,这不就是很简单的二分法吗。当时在纸上写的,半真半伪。大概如下
int bs(int arr[],size_t left,size_t right){
size_t middle = (left+right)/2;
if(middle==lefft || middle==right){
return -1;
}
if(arr[middle-1]<arr[middle] && arr[middle]>arr[middle+1]){
return arr[middle];
}
if(arr[middle-1]<arr[middle] && arr[middle]<arr[middle+1]){
return bs(arr,middle,right);
}
if(arr[middle-1]>arr[middle] && arr[middle]>arr[middle+1]){
return bs(arr,left,middle);
}
}
int x = bs(arr,0,arr.size());第一面完了让我回去等通知,我以为没戏了,结果第二天猎头告诉我通过了,让我等待第二面
第二面
第二面是电话面试,据说是交叉面,整个过程大约1小时,最后有个在线写代码环节。
自我介绍
略
说说你做过的个人觉得最有挑战性的一个案例
略
美团的猜你喜欢你觉得是怎么实现的?
猜你喜欢,个人觉得有两方面,1个就是我和某人比较相似(比如地域,年龄,口味等),然后他经常点的餐馆或菜品可以推荐给我。2个就是我经常点肯德基,而肯德基与麦当劳,汉堡王很类型,所以可以给我也推推麦当劳汉堡王。
推荐的时候,店铺与店铺,店铺与人,人与餐怎么联系的
店铺有很多的属性,比如位置,价位,辣不辣,品类等,每个属性都是一个维度的向量,然后进行余弦相似度计算,在一定的值以内的就算是相似。店铺与人,人与餐就是我刚刚讲过的。我和某人的属性的余弦相似度很高,那么可以把它喜欢的推荐给我。
你对余弦相似度了解多少?说说它的缺点
余弦相似度就是我们高中学过的向量计算,不过我们那会只有2维,而推荐这个是多维的。他呢计算比较简单,但是每个向量是对等的,实际上的向量不对等,比如猜你喜欢,对于餐品推荐来说,地域和价格的权重肯定比其他属性高。这一点没法体现。还有就是余弦相似度是两两对比,如果对象很多,比如一亿的话,两两对比实在太慢,我在微博的时候,我们微博头条在判断文章重复的时候,用过minhash和simhash,就是采取一个统一尺度,这样可以先根据某文算出相似的范围,然后在这个范围内去对比。
在线写代码,找兄弟词
在线写代码,对方向我邮箱发了一个网址,点开后就是一个在线写代码的网页,我本来想show一把c++的,后来一想c++的宽字符实在是个大坑,所以最后只好用python搞,题目如下
有个文件,里面有很多词,每个词一行。现在给你一个词,你需要找出这个文件里,该词的所有兄弟词,兄弟词的意思就是字相同,位置不同,比如abc的兄弟词就是acb,bac,bca,cab,cba等.
我写的还是比较轻松的
def gen_x_code(words):
arr = map(lambada word:ord(word),words).sort()
fingerprint=''.join(arr)
return fingerprint
def find(given):
given_fp = gen_x_code(given)
brothers = []
with open('words.txt','r') as f:
while line=f.readline():
if given_fp == gen_x_code(line.strip()):
brothers.append(line.strip())
return brothers
第三面
第三面是电话面,没有涉及技术,只是问了我过去的经历,职业规划什么的,并告诉我,第四面是总监面,他喜欢问算法,让我好好准备
第四面
第四面等了好久,而且是某天晚上九点多突然来电话说是进行面试,那时我已经躺着床上了,只好爬起来面试
自我介绍
略
介绍一下最难的项目
略
算法题
abcde,打乱顺序能组成哪些字符串,设计一个算法
我回答用个表格,依次为abcde,从上往下走,用一个set记录走过的格子就可以了。
第四面时间很短,总共不到半小时。
总结
第二天,猎头告诉我第四面没过。蚂蚁金服的面试到此结束了,前后脚经历了将近一个月。
个人的心路历程从第一面有些忐忑,到后面越来越有精神,感觉胜利近在咫尺。到最后被pass。
感觉蚂蚁的面试也不算特别难,最终被pass估计是因为过往经历不够出彩吧。