当我们在设计层级模型的时候,为了表示层级关系,经常会用一个指向父id的pid字段来处理,通过递归来获取各分类信息,这种方式简单明了,逻辑简单,但是当分类层级比较多的时候,递归的效率就不那么高了。有没有给力的办法呢?预排序遍历算法或许可以解决此问题。
预排序遍历算法可以看成一个树状结构,每个节点都有3个值,左(left),右(right),层级(level)如下图
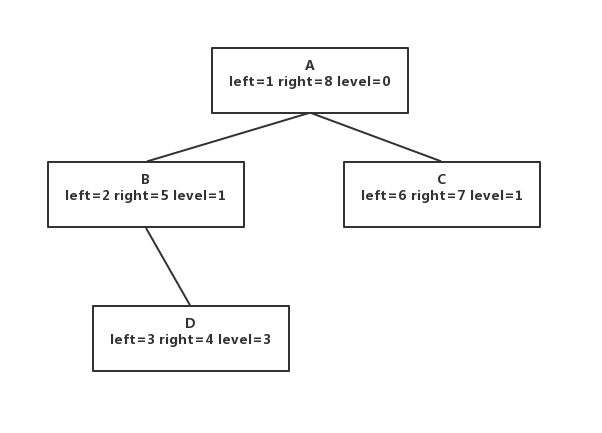
其实整个模型就像一跟绳子,如下图红线标注

通过图我们大概可以看出三个规律
- 子节点的left值一定大于父节点;子节点的right值一定小于父节点
- 如果一个节点没有子节点,那么它的left和right值就是连续的。
- 基于1,2点以及观察,可以得出一个节点的子节点数量=(right-left+1)/2-1,如
A :(8-1+1)/2-1 = 3
我们要得到一个节点(:left,:right,:level)的子节点的信息,可以用sql语句:
select * from table where left >:left and right <:right
可以看出,找出一个节点的子节点,已经找出指定level的子节点都是很容易的,但是,怎么添加一个节点呢?比如我们在D节点下添加一个节点E.如图:
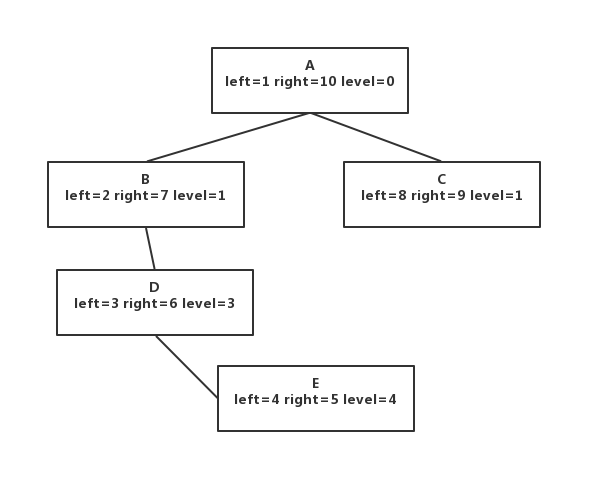
添加的sql语句大概是insert into table set(left,right,level) values(3+1,3+2,3+1);
但是可以看到,凡是left>4或right>5的节点都要改变,sql语句是update table set left =left+2,right=right+2 where right>=4;
同理,删除一个节点也得两步
update table set left =left-2,right=right-2 where left>3;
delete from where left = 3;
很显然,添加或删除的时候,除了自身的改变,还会改变其他行的数据,所以需要锁表,也可以使用存储过程。如
LOCK TABLE `table` WRITE;
SELECT @myLeft := left, @myRight := right, @myLevel
FROM `table`
WHERE left= 3;
DELETE FROM `table` WHERE left = @myLeft;
UPDATE `table` SET right = right - 2 WHERE right > @myRight;
UPDATE `table` SET left = left - 2 WHERE left > @myRight;
UNLOCK TABLES;总结一下:
可以看出,这种方法虽然读取比较简单,但是,插入删除却很麻烦。
但是考虑分类信息是读远大于写,所以这种方法还是合适的。